
今天无意间发现我的两个站点访问速度都非常缓慢,登录阿里云后台看了ECS服务器才发现CUP的使用率经常达到99-100%,看了日志才发现yisouspider(一搜蜘蛛,现在应该是属于神马的)蜘蛛正在疯狂爬行,就算是我在robots.txt设置了禁止爬行的路径也被爬行了。如果是凌晨爬行就不说了,竟然是在大白天疯狂爬行,分分钟可以搞瘫我们的站点,度娘一下发现有很多人都在吐槽这个yisouspider,最终的解决方案就是直接禁止yisouspider的爬行和访问。
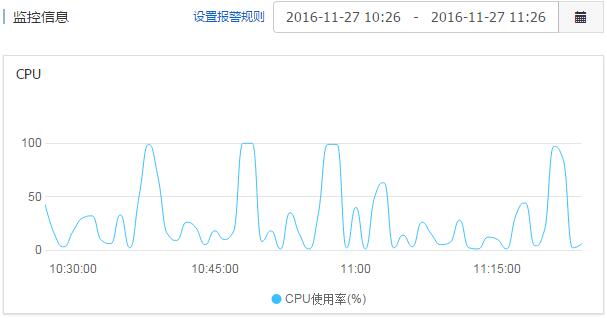
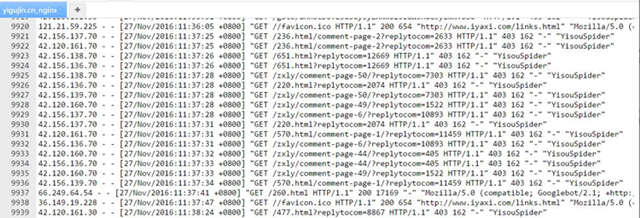
yisouspider爬行robots文件禁止的路径
UC社区神马搜索中给出的解释:
robots.txt是搜索引擎访问网站时要访问的第一个文件,以确定哪些网页是允许或禁止抓取的。yisouspider遵守robots.txt协议。如您希望完全禁止神马访问或对部分目录禁止访问,您可以通过robots.txt文件来设置内容,限定yisouspider的访问权限。
如果您开通了CNZZ云推荐服务,协议中默认支持yisouspider抓取,会忽略robots.tx文件协议的限制。
限定Yisouspider访问权限的robots协议写法
robots.txt必须放在网站根目录下,且文件名要小写。
具体写法:
1) 完全禁止yisouspider抓取:
User-agent: yisouspider
Disallow: /2) 禁止yisouspider抓取指定目录
User-agent: yisouspider
Disallow: /update
Disallow: /history禁止抓取update、history目录下网页
不过我也懒得折腾这个针对yisouspider的robots协议,我还是直接在nginx里面禁止yisouspider来得更有效果。
Nginx屏蔽爬虫yisouspider访问站点方法:
进入到nginx安装目录下的conf目录,将如下代码保存为 agent_deny.conf
#禁止Scrapy等工具的抓取
if ($http_user_agent ~* (Scrapy|Curl|HttpClient)) {
return 403;
}#禁止指定UA及UA为空的访问
if ($http_user_agent ~ "yisouspider|FeedDemon|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms|^$" ) {
return 403;
}#禁止非GET|HEAD|POST方式的抓取
if ($request_method !~ ^(GET|HEAD|POST)$) {
return 403;
}然后,在网站相关配置中的
location / {
try_files $uri $uri/ /index.php?$args;下方插入如下代码:
include agent_deny.conf;保存后,执行如下命令,平滑重启nginx即可:
/usr/local/nginx/sbin/nginx -s reload懿古今和boke112百科站点就是使用这个方法成功屏蔽爬虫yisouspider访问。设置好之后,我的ECS服务器CPU的使用率立马就降下来了。
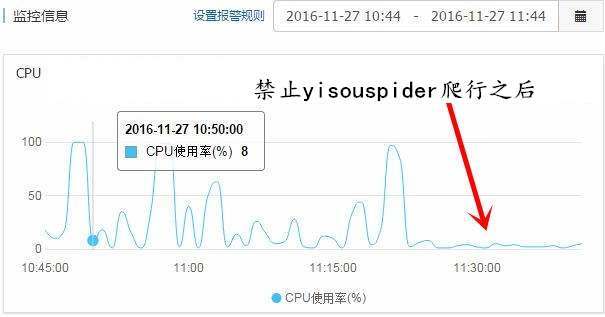
根据百度统计给出的数据,我的站点来自神马搜索的不多,所以权衡之下只能禁止yisouspider蜘蛛爬行了,要不然我的站点经常被它搞瘫了就得不偿失了。如果你的服务器比较给力,不会被搞瘫的话,就没必要禁止它了。
PS:请允许我用小心之心揣测,以前使用阿里云免费虚拟主机每个月都会出现资源耗尽,最大的问题很有可能就会被yisouspider蜘蛛爬行导致的。
Apache屏蔽爬虫yisouspider访问站点方法:
1、通过修改 .htaccess文件
修改网站目录下的.htaccess,添加如下代码即可(2种代码任选):
可用代码 (1):
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} (^$|yisouspider|FeedDemon|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms) [NC]
RewriteRule ^(.*)$ - [F]可用代码 (2):
SetEnvIfNoCase ^User-Agent$ .*(yisouspider|FeedDemon|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms) BADBOT
Order Allow,Deny
Allow from all
Deny from env=BADBOT2、通过修改httpd.conf配置文件
找到如下类似位置,根据以下代码 新增 / 修改,然后重启Apache即可:
DocumentRoot /home/wwwroot/xxx
<Directory "/home/wwwroot/xxx">
SetEnvIfNoCase User-Agent ".*(yisouspider|FeedDemon|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms)" BADBOT
Order allow,deny
Allow from all
deny from env=BADBOT
</Directory>PHP代码屏蔽爬虫yisouspider访问站点方法:
将如下方法放到贴到网站入口文件index.php中的第一个 <?php 之后即可:
//获取UA信息
$ua = $_SERVER['HTTP_USER_AGENT'];
//将恶意USER_AGENT存入数组
$now_ua = array('yisouspider','FeedDemon ','BOT/0.1 (BOT for JCE)','CrawlDaddy ','Java','Feedly','UniversalFeedParser','ApacheBench','Swiftbot','ZmEu','Indy Library','oBot','jaunty','YandexBot','AhrefsBot','MJ12bot','WinHttp','EasouSpider','HttpClient','Microsoft URL Control','YYSpider','jaunty','Python-urllib','lightDeckReports Bot');
//禁止空USER_AGENT,dedecms等主流采集程序都是空USER_AGENT,部分sql注入工具也是空USER_AGENT
if(!$ua) {
header("Content-type: text/html; charset=utf-8");
die('请勿采集本站,因为采集的站长木有小JJ!');
}else{
foreach($now_ua as $value )
//判断是否是数组中存在的UA
if(eregi($value,$ua)) {
header("Content-type: text/html; charset=utf-8");
die('请勿采集本站,因为采集的站长木有小JJ!');
}
}附录:UA收集
下面是网络上常见的垃圾UA列表,仅供参考,同时也欢迎你来补充。
yisouspider 一搜蜘蛛
FeedDemon 内容采集
BOT/0.1 (BOT for JCE) sql注入
CrawlDaddy sql注入
Java 内容采集
Jullo 内容采集
Feedly 内容采集
UniversalFeedParser 内容采集
ApacheBench cc攻击器
Swiftbot 无用爬虫
YandexBot 无用爬虫
AhrefsBot 无用爬虫
YisouSpider 无用爬虫(已被UC神马搜索收购,此蜘蛛可以放开!)
MJ12bot 无用爬虫
ZmEu phpmyadmin 漏洞扫描
WinHttp 采集cc攻击
EasouSpider 无用爬虫
HttpClient tcp攻击
Microsoft URL Control 扫描
YYSpider 无用爬虫
jaunty wordpress爆破扫描器
oBot 无用爬虫
Python-urllib 内容采集
Indy Library 扫描
FlightDeckReports Bot 无用爬虫
Linguee Bot 无用爬虫

发表于2016-11-28 08:21 沙发
很好的分享,谢谢博主
发表于2016-11-28 09:05 板凳
我的是抓取太少,你是屏蔽,哎
@唯历史这个一搜蜘蛛每次一来就搞死我主机,所以只能直接屏蔽了
发表于2016-11-28 09:16 地板
我的来源神马比其他搜索引擎的要多。
@Koolight看来贵站移动端来源还是挺多的,我的主要还是百度
@懿古今[色] 你们的站点,都有搜索流量,太令人羡慕了!
发表于2016-11-28 10:28 4楼
第一次见这种来源
发表于2016-11-28 11:46 5楼
建议升级主机 而不是屏蔽~~~ [晕]
@木庄网络博客收录量少而且来路也几乎没有,所以我宁愿直接屏蔽它了
发表于2016-11-28 12:46 6楼
我觉得用cnzz这种东西就是开门揖盗。
@大致最主要是不遵守robots协议,要不然也不会这么郁闷
发表于2016-11-28 15:54 7楼
[微笑] 目前还不想屏蔽这个“一搜蜘蛛”,以后会不会看情况再说(爬的确实过于勤快了些)!
@我爱动感单车网[偷笑] 等你被它多搞几次服务器资源耗尽你就知道它的厉害了
@懿古今到时再说!
发表于2016-11-28 16:56 8楼
robots很老的套路啦///
发表于2016-11-28 17:40 9楼
BAT三家,软件服务兼容性、稳定性最好的是T,B有战术没战略,A有战略没战术。B的东西做的还不错,根子里有问题。A的大方向不错,但是东西做的,很感人。哪怕是收购前很好的东西,收了以后越做小问题越多。
发表于2016-11-28 20:25 10楼
不是都说要吸引蜘蛛吗、?
@分钱榜蜘蛛也要区分对待的,比如这个,每次来都搞到我服务器死机,而且收录和来路都比较少,我就直接屏蔽它了
发表于2016-11-28 23:55 11楼
[坏笑] 这两天跑去军哥那边问清楚了,https跟http可以在同一个服务器共存。 [偷笑] 等万网虚拟主机到期时,就搬家,都放到一起,省得我还要思考买什么服务器。届时再来各种优化网站!
@橘子书我现在两个站共用一个服务器,感觉挺好的,缺点就是一旦服务器有问题,两个站点都无法访问。
@懿古今[偷笑] 我两个都是小站,有时候日ip就一两个,所以,不太担心服务器问题,自己别乱搞,一般不会有什么问题。
@橘子书准备换成什么的?
@我爱动感单车网原来打算再买一台ecs,不过现在想直接放在同一个服务器就好了。不是靠网站吃饭,所以不再去计较seo等一切自己不拿手的事。
发表于2016-12-01 19:48 12楼
我在服务器上测试https,导致的整个服务器网站都无法访问,只能还原后就没事了。更不上潮流了。
@热腾网HTTPS我都还没敢折腾呢,觉得还是等以后再流行一些再折腾
发表于2017-01-07 14:18 13楼
还好这蛛没有看上我的站~
@羽中我已经屏蔽了,这个蜘蛛太狠了
发表于2019-05-27 14:23 14楼
YandexBot 这个垃圾也在爬我的,我看了下才收录我十几个页面,一天比Google还勤快。
@奶爸de笔记这个好像说是德国还是那个国家的爬虫,感觉没什么用
发表于2019-12-31 15:31 15楼
费那劲还改nginx,yisouspider这个爬虫是阿里的,这几天开始爬我的站,我直接在cdn里把阿里全部服务器ASN屏蔽就结了。正常用户也不会用阿里的主机ip去访问你网站
发表于2020-03-06 14:49 16楼
大家有见过一个名为 AspiegelBot 的爬虫吗?
@乌帮图这个倒是第一次听说,没有遇到过这个爬虫
发表于2023-02-23 16:41 17楼
我不能复制
@QQ游客已经修改过了,将鼠标放到代码上,点击【复制】即可成功复制代码